综述:深度学习在蛋白质结构预测中的最新进展
1. 问题引入
-
长期以来,结构生物信息学领域一直使用机器学习方法,尤其是人工神经网络(NN)模型。PHD,PSIPRED和JPred是当今仍广泛使用的早期NN方法的杰出代表。
-
DNN对CASP产生重大影响的第一个应用领域是残基-残基接触预测,这在CASP12和13中的准确性上有特别明显的提高。在CASP13中,一些小组将这些技术进一步扩展到了原子间距离的预测,在某些情况下可以将其直接用于精确的三级结构生成。
-
文章贡献
- 为CASP参与者和观察者提供对最重要的、已在最近的CASP实验中成功应用于核心问题领域的DNN体系结构工作的理解。
- 讨论这些模型相对于在各个领域中传统使用的模型可能具有的优势。
- 对这些模型为何以及如何工作、它们的局限性、潜在的缺陷以及正确的应用进行一些讨论。(所有讨论将仅限于监督学习模型,因为迄今为止在CASP中使用的性能最高的DNN模型就是这种类型)
2. 蛋白质结构预测中使用的卷积神经网络
-
感受野
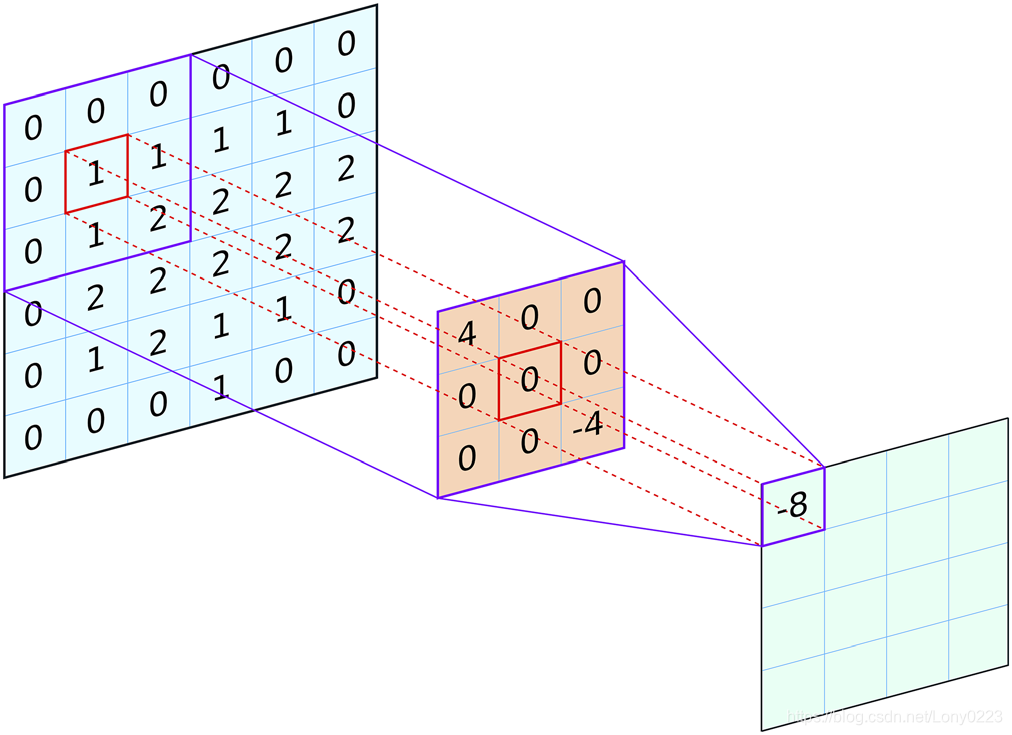
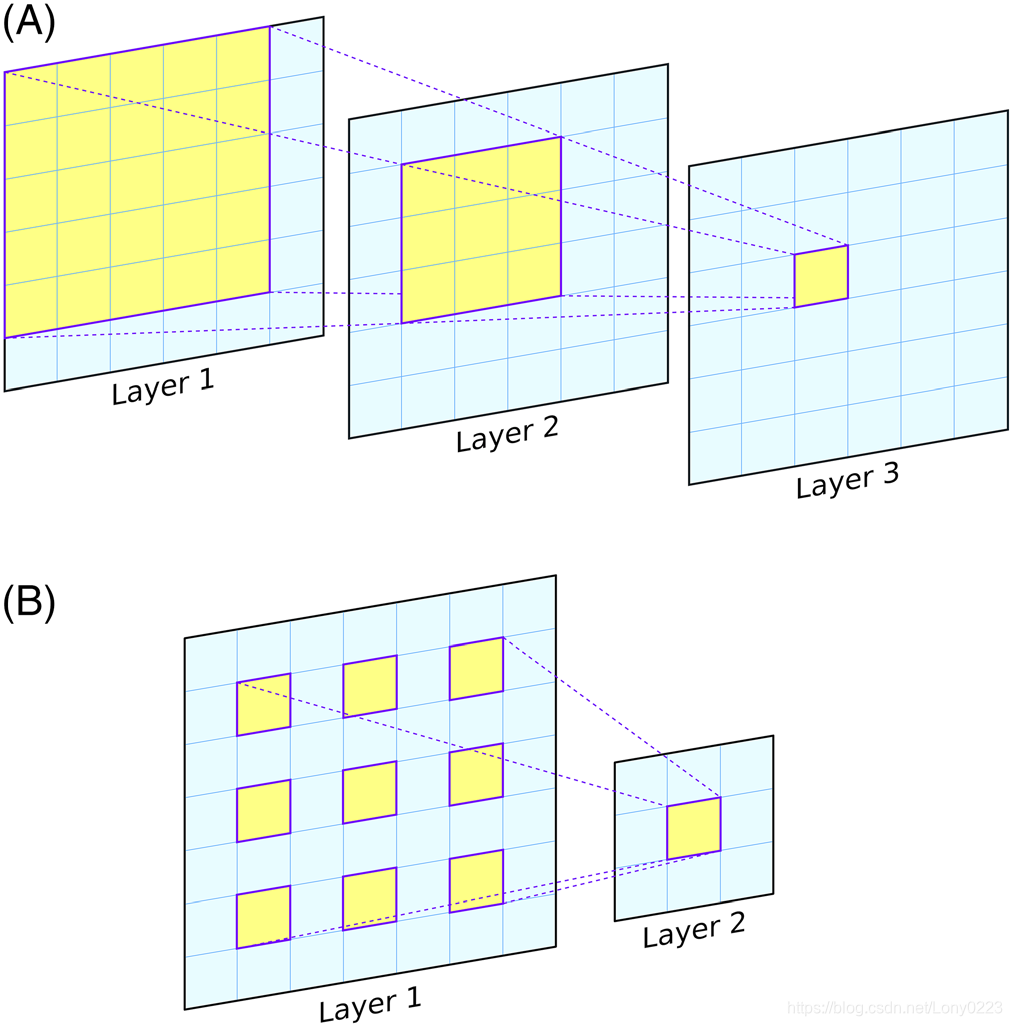
这仅是指可以随时看到输入图像的区域(或更一般地说,输入特征集)。具体而言,感受野是用于计算单个输出值的输入的空间范围,通常是针对网络中给定卷积层(最常见的是最后一个)中的单个神经元计算的。由单层3×3卷积核组成的网络中的输出神经元将具有3×3的感受野,因为网络对每个输出像素进行的最终计算仅考虑输入中的中心像素及其直接邻居(图 1)。但是,将模型与连续的卷积层组合在一起,可以增加感受野;即每个输入像素周围的区域,可以在计算最终层的输出时将其包括在内(参见图2A)。需要注意的是,感受野的大小受输入大小的限制;可以通过添加更多的卷积层使得CNN具有较大的感受野,但是如果CNN仅在尺寸为32×32的输入上运行,则无论层数如何——即使其“理论”感受野可能更大,实际感受野只能增长到最大尺寸32×32。实际上,最大感受野必须足够大以捕获输入数据中的相关结构。
-
扩张卷积也可以用来以更少的层数来增加感受野。
在扩张卷积中,通过在每个像素之间包含空格来拉伸每个卷积核(图2B)。扩张率为2的3×3卷积核实际上将与5×5卷积核覆盖相同的区域,但是仅具有9个可学习的参数,而不是25个(图2B)。不利的一面是,扩张卷积核只能采样25个像素中的9个,因此会有间隙。但是,这些间隙可以由后来的扩张卷积层填补,因此由扩张卷积层构成的网络可以覆盖任意大的感受野,而无需成倍地增加可学习的参数。 在CASP13中,扩张卷积用于许多性能最高的CNN模型中。
-
CNN模型能够接受图像类型的输入并产生图像类型的输出。
该类型网络通过全卷积网络(FCN;不要与全连接网络相混淆)实现,全部由一堆卷积层组成,一直到输出为止,而没有改变图像分辨率或丢失图像结构的最大池化层或全连接层。因此,FCN的特性是它们可以设置产生与输入尺寸完全相同的输出图像。一个典型应用是获取图像并生成一个与其大小相同的输出图像,该输出图像突出显示输入图像中的特定对象,这被称为图像分割。在结构生物信息学中,这种类型的体系结构已被许多小组用于联系预测中,其中网络的输入是一个或多个特征,取决于目标序列的(平方)长度 (例如氨基酸协方差矩阵),并产生相同形状的输出(接触图)。
-
用于距离预测的CNN
由于残基协方差矩阵与接触图之间的对应关系, 将其视为类似于图像的输入,以得出映射是很自然的。CNN非常适合此类预测问题,因为卷积层的关键思想是识别局部模式,而不管其在输入中的空间位置如何。举例来说,将这个想法带入接触预测领域,将卷积过滤器应用于氨基酸协方差矩阵,可以使模型检测由任意数量的残基分隔的局部序列基序之间的相互作用,与观察到的结构模式非常吻合 (例如,可以适应可变长度的循环甚至整个域插入,而无需更改模型)。
乍看之下,CNN模型(其中关键功能单元仅设计为使用数据的局部子集)可以胜过全局模型(在该模型中同时考虑所有残基协方差数据),这一事实似乎令人惊讶。另一方面,栈式连续卷积层以增加模型的总体感受野的能力在理论上使模型可以在预测单个接触时根据需要使用目标蛋白的尽可能多的协变数据。在最近的工作中,我们创建了具有不同大小的感受野的CNN模型,以评估是否有必要对协变数据进行完整的全局查看,以便在预测接触时获得高精度。我们发现,增加网络的感受野可以提高精度,这是可以预期的,但是只有在最大感受野大小达到15个残基左右时,才能实现显着的增益。感受野大小的进一步增加(最高达估计的最大值49)导致平均精度几乎没有提高。
3. 为什么深度学习有用
最后,该文章对于基于DNN的模型能够有效解决各种问题的原因进行分析;针对一些潜在的缺陷提出了展望。
-
知识的层次表示
当DNN中的每个层组成前一层的输出时,可以在不同的抽象级别上学习数据的特征,从而使更深的模型能够识别日益复杂的模式。这种学习层次特征的能力在各种结构性生物信息学任务中很有用,因为生物学数据中的信息通常确实存在于层次结构的各个级别。例如,在蛋白质中,信息存在于各个残基,序列基序,片段,二级和超二级结构,域等的层次水平。 -
深度学习作为邻域密度估计方法
过拟合使得模型泛化性能降低;欠拟合使得模型精度下降 -
对缺失或带噪声的输入的鲁棒性
-
潜在缺陷
- 过拟合与泛化性能
与诸如文本或图像之类的应用领域相比,生物信息学数据库通常具有可用于训练预测模型的数据点少得多。由于DNN模型经常具有数百万个可调整的参数,因此,对于足够少的训练示例,DNN可能容易被过度训练并记忆训练集,如上所述。过度训练的模型可能面临的最大问题是,在将模型应用于新问题实例之前,我们可能会高估它们的性能。 - 如何解决
确保用于基准测试的测试集中没有与训练集中的任何蛋白质具有相似3D结构或折叠的蛋白质。
- 过拟合与泛化性能
4. 展望
- 深度学习显然正在席卷生物信息学。如本文所述,这是由于深度学习模型能够考虑数据中不同层次的结构,处理嘈杂的数据,无需特征工程即可获取原始特征并明智地插值以对训练中未使用的数据做出合理的预测。
- 由于以下几个原因,这种趋势可能会持续至少几年:
- 硬件,架构和算法的不断改进;
- 不断增加的实验数据收集;
- 机器学习和生物信息学界之间越来越多的交叉。
- 随着生物信息学的深度学习进入更成熟的阶段,严格的基准测试和评估在已发表的文献中变得越来越普遍是至关重要的。当然,生物信息学的最终目的不仅在于预测任务的准确性,还在于对工作中潜在的生物学过程的理解。随着对NN的可解释性的研究的改进,对生物信息学中成功的网络进行研究以了解哪些特征和信号有用是很重要的。这样的理解甚至可以用来帮助网络本身变得更加健壮和准确。